Introduction to lsframe¶
The aim of lsframe is to provide a simple tool for building and interacting with pandas DataFrames that have columns defined by specific language and dates extracted from file and folder names, and populated with outputs of processing functions. Users establish a DataFrame using file and folder names then define a function that operates on those files and folders to return data that can be correlated with the language in the file and folder names. Built-in methods for organization, manipulation, and display of the data in the DataFrame make visualization of trends and correlations quick and simple.
General Overview¶
Imagine this directory, and imagine you would like to analyze the contents of the folders as a function of the sample number.
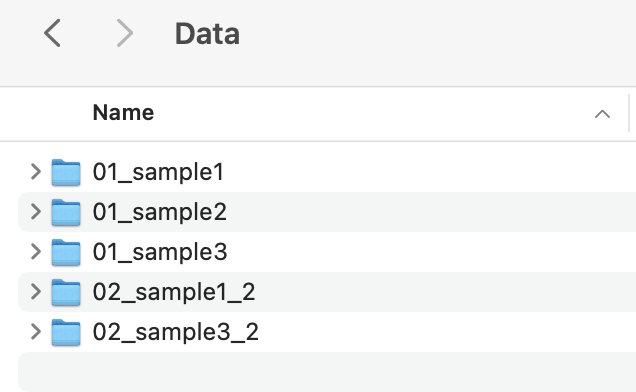
Example parent directory¶
First create an object that contains a frame with the first column being a list of names of the files or folders in a parent directory,
import lsframe as ls
path = '/path/to/directory/'
lsobject = ls.start(path)
Use Language Patterns¶
Next define the patterns to use for classification. If a single pattern or list of patterns is given, additional columns will be added with names according to the patterns. The most basic behavior provides a bool indicating whether or not the pattern was found. This example adds the column 'sample1' and puts True where found, False where not found,
path = '/path/to/directory/'
lsobject = ls.start(path, patterns='sample1') # single pattern
lsobject = ls.start(path, patterns=['sample1', 'sample2', 'sample3']) # list of patterns
You may also use regular expressions to do more sophisticated pattern searches and classify by specific language rather than bool. To do this, use a dictionary rather than a list. The keys of the dict are the column names, the values are the expression to search for and classify by. This example creates a column called 'sample' and classifies by any one digit number found just to the right of the word 'sample',
path = '/path/to/directory/'
lsobject = ls.start(path, patterns={'sample': 'sample\d'})
If this patterning is not found, False is entered.
To mix these behaviors, add bool for the dict value and the column for the key is added with True or False added if the pattern is or is not found, respectively. This example makes a column for 'sample' and classifies by any one digit number as above, but also adds a column called 'blank_run' and classifies as True or False.
path = '/path/to/directory/'
lsobject = ls.start(path, patterns={'sample': 'sample\d', 'blank_run': bool})
Skip Files or Folders¶
You may skip directories according to specific language. This example classifies by sample number but skips any file or folder with 'sample7' in the name,
path = '/path/to/directory/'
lsobject = ls.start(path, patterns={'sample': 'sample\d'}, skip='sample7')
Find Dates¶
Now imagine the folder names include dates,
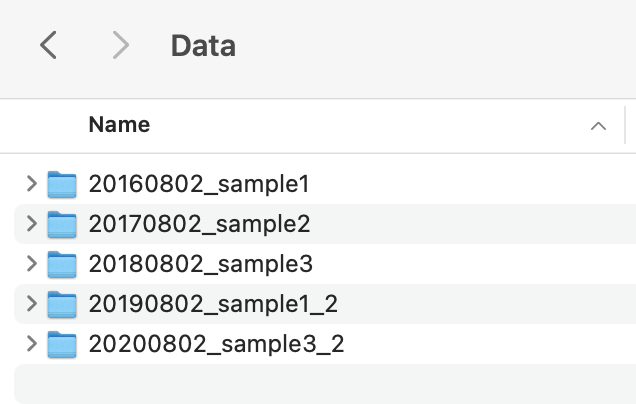
Example parent directory¶
You may also classify by dates found in file or folder names and the days elapsed since the found date. This example looks for dates of the format 'YYYYMMDD' and adds 'date' and 'date_delta' columns,
path = '/path/to/directory/'
lsobject = ls.start(path,
patterns={'sample': 'sample\d'},
skip='sample7',
date_format='YYYYMMDD'
)
You can search for all possible dates by setting date_format='any'. This finds all logical dates and gives them as a list, along with a date_delta list and a date_format list. For example,
path = '/path/to/directory/'
lsobject = ls.start(path,
patterns={'sample': 'sample\d'},
skip='sample7',
date_format='any'
)
Use a Custom Function¶
You can also use a custom function that operates on each element of the parent directory to add the outputs as classifiers, rather than just a bool. Do this by adding the names of the classifier columns, defining the function call, and adding any needed arguments in the form of a dictionary. For example, if the function is:
def function_handle(directory, args_dict):
use_directory = directory
output1 = random.randint(0, args_dict['par1'])
output2 = random.randint(args_dict['par1'], args_dict['par2'])
return [output1, output2]
Create the object,
lsobject = ls.start(path,
patterns={'sample': 'sample\d'},
skip='sample7',
date_format='any'
classifiers=['output1', 'output2'],
function=function_handle,
function_args={'par1': 1,
'par2': 2}
)
Call the drive() method
lsobject.drive()
and two new columns would be added called 'output1' and 'output2' with the values corresponding to the function outputs. Make sure to have the function accept a path and a single dictionary that contains any additional parameters needed. Also make sure the function returns the outputs in a list that is equal in length to the given list of classifiers. Use the above example function as a template.
Handle Function Errors¶
If the function errors on the specific file or folder "null" is returned for the classifier to facilitate easy removal of any file or folder that is not compatible with the function using something similar to,
lsobject.frame = lsobject.frame[lsobject.frame['output1'] != 'null']